
0%完成率!Claude、GPT、Gemini 全灭,SWE-Bench作者新作把AI圈干沉默了
0%完成率!Claude、GPT、Gemini 全灭,SWE-Bench作者新作把AI圈干沉默了SWE-Bench 的创建者,刚刚又放出了一个地狱级新 benchmark。
来自主题: AI技术研报
10308 点击 2026-05-07 15:31
 搜索
搜索
SWE-Bench 的创建者,刚刚又放出了一个地狱级新 benchmark。
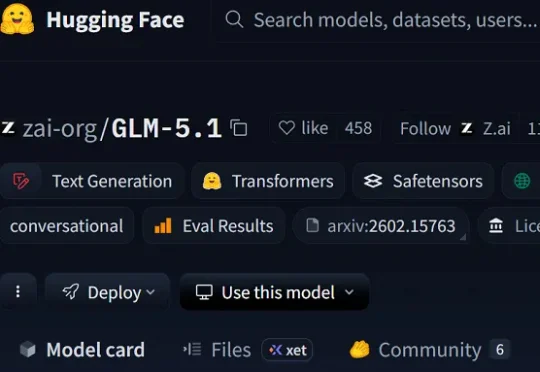
今天,智谱正式开源其最强模型GLM-5.1,这一模型在专业软件开发基准测试SWE-Bench Pro中,GLM-5.1刷新全球最佳成绩,得分达到58.4,超过了GPT-5.4、Claude Opus 4.6等已经正式发布的闭源模型,和MiniMax M2.7、Kimi K2.5等开源模型。
在 Princeton 发布 SWE-Bench 之后,用真实世界代码仓库+可执行测试评测大模型软件工程能力,几乎已成为学术界与工业界的共识。围绕 SWE issue 的评测范式迅速发展,也催生了一系列 SWE 系列 benchmark,在刻画模型 bug 修复能力方面发挥了重要作用。
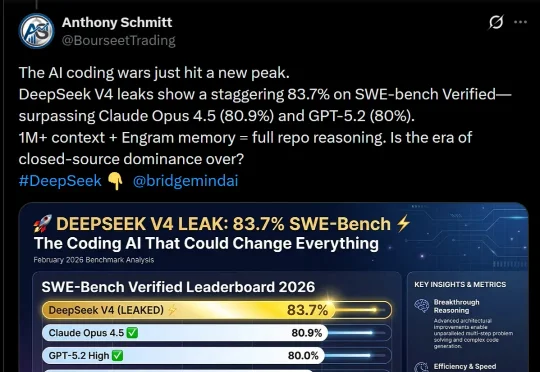
DeepSeek V4,据说明天就要上线了?这是首个匹敌顶尖闭源模型的开源模型,被网友评为「一鲸落万物生」。泄露的基准测试显示,它在SWE-bench Verified上取得了83.7%,已经超越Opus 4.5和GPT-5.2!
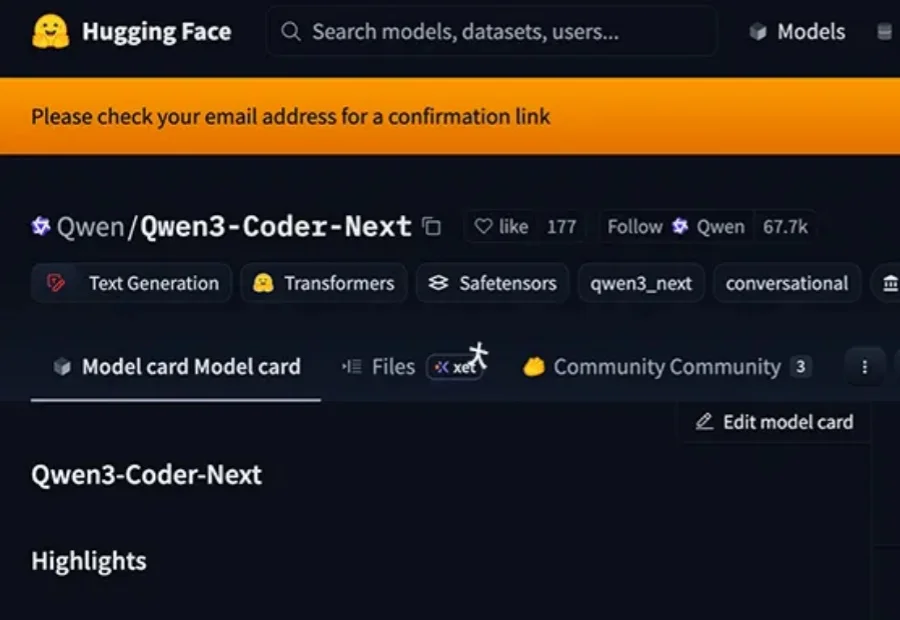
个人电脑也能跑出顶级编程智能体?今日凌晨,阿里开源了一款小型混合专家模型Qwen3-Coder-Next,专为编程智能体(Agent)和本地开发打造。该模型总参数80B,激活参数仅3B,在权威基准SWE-Bench Verified上实现了超70%的问题解决率,性能媲美激活参数规模大10-20倍的稠密模型。
今天是一期硬核的话题讨论: Coding Agent 评测。 AI 编程能力进步飞速,在国外御三家和国产中厂四杰的努力下,AI 编程基准 SWE-bench 的分数从年初的 30% 硬生生拉到了年底的
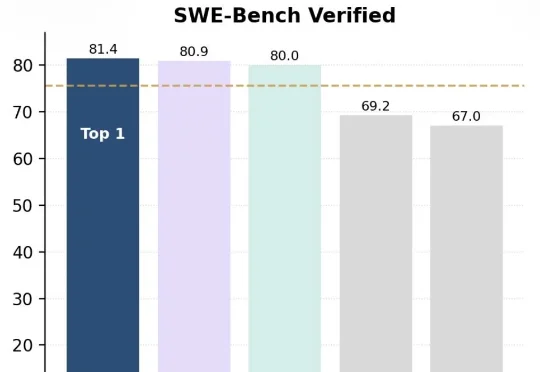
又一个中国新模型被推到聚光灯下,刷屏国内外科技圈。IQuest-Coder-V1模型系列,看起来真的很牛。在最新版SWE-Bench Verified榜单中,40B参数版本的IQuest-Coder取得了81.4%的成绩,这个成绩甚至超过了Claude Opus-4.5和GPT-5.2(这俩模型没有官方资料,但外界普遍猜测参数规模在千亿-万亿级)。
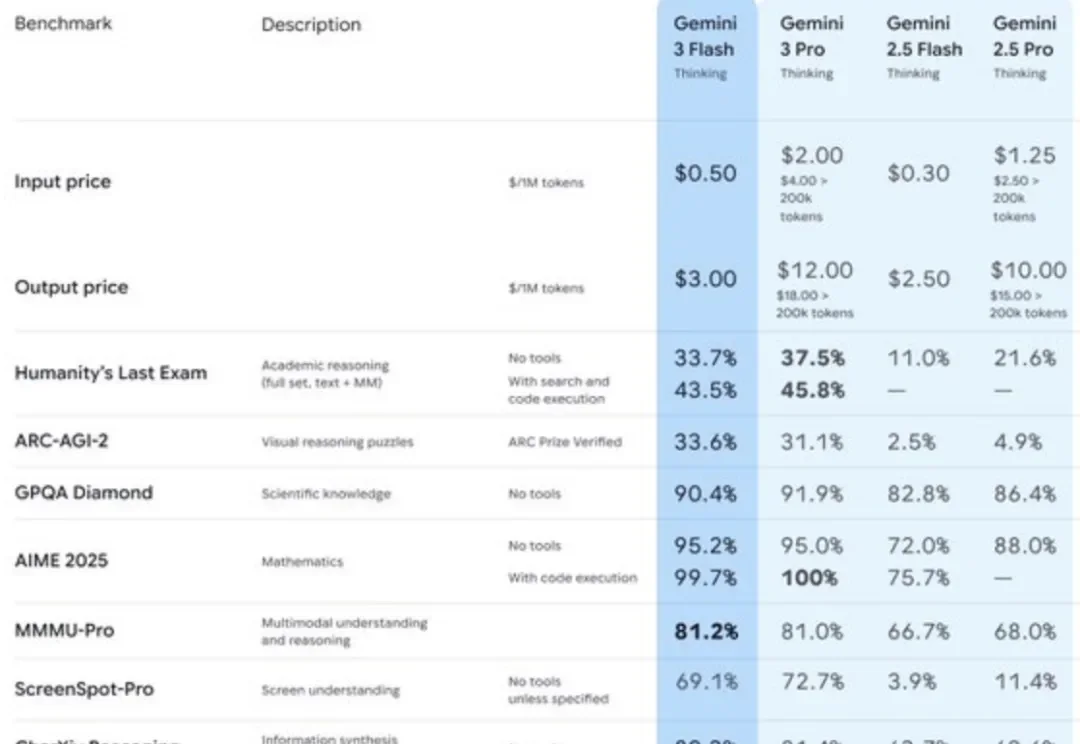
倒反天罡! Gemini 3 Flash的表现在SWE-Bench Verified测试中获得了78%的分数,比超大杯Pro还略胜一筹。

来自中国的初创团队词元无限给出了自己的答案。由清华姚班校友带队设计开发的编码智能体 InfCode,在 SWE-Bench Verified 和 Multi-SWE-bench-CPP 两项非常权威的 AI Coding 基准中双双登顶,力压一众编程智能体。

学界杀入主赛道!UCL 校园团队 EuniAI 抛出开源智能体 Prometheus,在 SWE-bench Verified 上 71.2% Pass@1、主榜实锤合并;成本低至 $0.23/issue。